PufferDrive 2.0: A fast and friendly driving simulator for training and evaluating RL agents
Daphne Cornelisse1*, Spencer Cheng2*, Pragnay Mandavilli1, Julian Hunt1, Kevin Joseph1, Waël Doulazmi3, 4, Valentin Charraut4, Aditya Gupta1, Joseph Suarez2, Eugene Vinitsky1
1 Emerge Lab at NYU Tandon School of Engineering | 2 Puffer.ai | 3 Centre for Robotics, Mines Paris - PSL | 4 Valeo | * Shared first contributor
December 30, 2025
We introduce PufferDrive 2.0, a fast, easy-to-use driving simulator for reinforcement learning (RL). Built on PufferLib, it allows you to train agents at 300,000 steps per second on a single GPU. You can solve thousands of multi-agent scenarios in just 15 minutes. Evaluation and visualization run directly in the browser. This post highlights the main features and traces the sequence of projects that led to PufferDrive 2.0.
Highlights
- Super-fast self-play RL: Train agents on 10,000 multi-agent Waymo scenarios and reach a near-perfect score in under in about 15 minutes on a single GPU where earlier results took 24 hours.
- Long-horizon driving: Train agents to reach goals indefinitely on large CARLA maps. Demo agents are trained this way. Drive alongside them in the browser below.
- Built-in evaluation: Integrated, accelerated eval support for the Waymo Open Sim Agent Challenge (WOSAC) and a human compatibility benchmark.
- Easy scenario creation: Edit or design custom scenarios in minutes, including long-tail and stress-test cases, using the interactive scenario editor.
- And more: Browse the docs for details.
Drive together with trained agents
Hold Left Shift and use arrow keys or WASD to control the vehicle. Hold space for first-person view and ctrl to see what your agent is seeing.
Tip
Make sure to click on the demo window first.
Introduction and history
Deep reinforcement learning algorithms such as PPO, work effectively in the billion-sample regime. With sufficient scale and occasional successes, RL can optimize well-defined objectives even under sparse reward signals.
This shifts the primary bottleneck to simulation. The rate at which high-quality experience can be generated directly determines how reliably RL can be applied to challenging real-world problems, such as autonomous navigation in dynamic, multi-agent environments.1
Over the past few years, we developed a sequence of data-driven, multi-agent simulators to study large-scale self-play for autonomous driving. Agents are trained from scratch. They generate their own experience by interacting with other agents in the environment and learn from it over time. In this post, we briefly summarize this progression and show how we arrived at PufferDrive 2.0.
Early results with self-play RL in autonomous driving
Nocturne showed that self-play RL could be promising for driving if we have access to a data-driven (grounded) simulator. Using maps from the Waymo Open Motion Dataset (WOMD), PPO agents trained from scratch in simulation achieved an 80% goal-reaching rate.
The main limitation was the cost of simulated experience. Nocturne ran at roughly 2,000 steps per second, so reaching this level of performance required about two days of training on a single GPU. It hinted that self-play RL could work, but generating the required experience was still expensive.
Scaling up
Later work explored what becomes possible once reaching scale is no longer a bottleneck.
- Gigaflow demonstrated that large-scale self-play alone can produce robust, naturalistic driving. With a batched simulator, it trained on the equivalent of decades of driving per hour and achieved strong performance across multiple benchmarks without human driving demonstrations.
- GPUDrive, built on Madrona, open-sourced a similar GPU-driven simulation approach. It explored a more minimal self-play setup with a simpler reward structure and narrower task scope. It demonstrated that effective collision avoidance and goal-reaching can be learned in roughly a day on a single consumer GPU.
These results suggested that once simulation becomes cheap, self-play RL can produce robust autonomous driving policies.
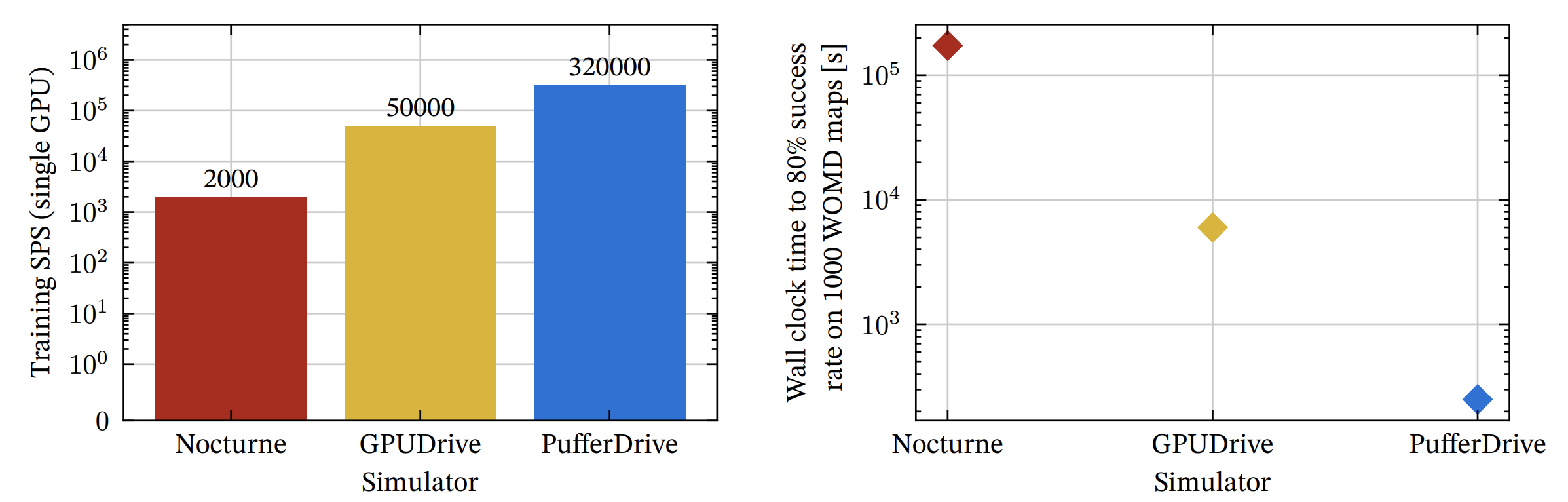 Figure 1: Progression of RL-based driving simulators. Left: end-to-end training throughput on an NVIDIA RTX 4080, counting only transitions collected by learning policy agents. Right: wall-clock time to reach 80 percent goal-reaching2. This captures both simulation speed and algorithmic efficiency.
Figure 1: Progression of RL-based driving simulators. Left: end-to-end training throughput on an NVIDIA RTX 4080, counting only transitions collected by learning policy agents. Right: wall-clock time to reach 80 percent goal-reaching2. This captures both simulation speed and algorithmic efficiency.
| Simulator | End-to-end training SPS | Time to 80% success rate |
|---|---|---|
| Nocturne | 2,000 | ~48 hours |
| GPUDrive | 50,000 | ~1.7 hours |
| PufferDrive | 320,000 | ~4 minutes |
From GPUDrive to PufferDrive
GPUDrive delivered high raw simulation speed, but end-to-end training throughput (~30K steps/sec) still limited experiments, especially on large maps like CARLA. Memory layout and batching overheads prevented further speedups.
We were motivated to get faster end-to-end training because waiting a full day for experimental results slows down everything, debugging, testing, and scientific progress. This led to the development of PufferDrive.
Partnering with Spencer Cheng from Puffer.ai, we rebuilt GPUDrive around PufferLib. The result, PufferDrive 1.0, reached ~200,000 steps per second on a single GPU and scaled linearly across multiple GPUs. Training agents on 10,000 Waymo maps took roughly 24 hours with GPUDrive—with PufferDrive, we now reproduce the same results in ~15 minutes.
Roadmap: PufferDrive 3.0
What is next? PufferDrive 3.0 will improve agent diversity, realism, and expand simulation capabilities. Priorities may shift as we test features and gather feedback. You can find an overview of our planned features on the project board or open an issue with something you would like to see!
Simulation and environment
- 2.5D simulation (allow for maps with overpasses, currently not supported)
Agent and interaction
- More efficient collision checking
- Support for traffic lights
- Variable agent numbers in CARLA maps
- Support for reward conditioning across a wide range of rewards
- A wide set of new rewards representing law-abiding driving
Benchmarks
- More extensive planning benchmark with human replays (more metrics)
Citation
If you use PufferDrive, please cite:
@software{pufferdrive2025github,
author = {Daphne Cornelisse⁕ and Spencer Cheng⁕ and Pragnay Mandavilli and Julian Hunt and Kevin Joseph and Waël Doulazmi and Valentin Charraut and Aditya Gupta and Joseph Suarez and Eugene Vinitsky},
title = {{PufferDrive}: A Fast and Friendly Driving Simulator for Training and Evaluating {RL} Agents},
url = {https://github.com/Emerge-Lab/PufferDrive},
version = {2.0.0},
year = {2025},
}
*Equal contribution
Notes
- A useful parallel comes from the early days of computing. In the 1970s and 1980s, advances in semiconductor manufacturing and microprocessor design—such as Intel’s 8080 and 80286 chips—dramatically reduced computation costs and increased speed. This made iterative software development accessible and enabled entirely new ecosystems of applications, ultimately giving rise to the personal computer. Multi-agent RL faces a similar bottleneck today: progress is limited by the cost and speed of experience collection. Fast, affordable simulation with integrated RL algorithms may play a similar role, enabling solutions that were previously out of reach.
- We benchmark here against 80% goal-reaching to make the results comparable to those in Nocturne. Similar accelerations are achieved against GPUDrive at the 99% success rate.